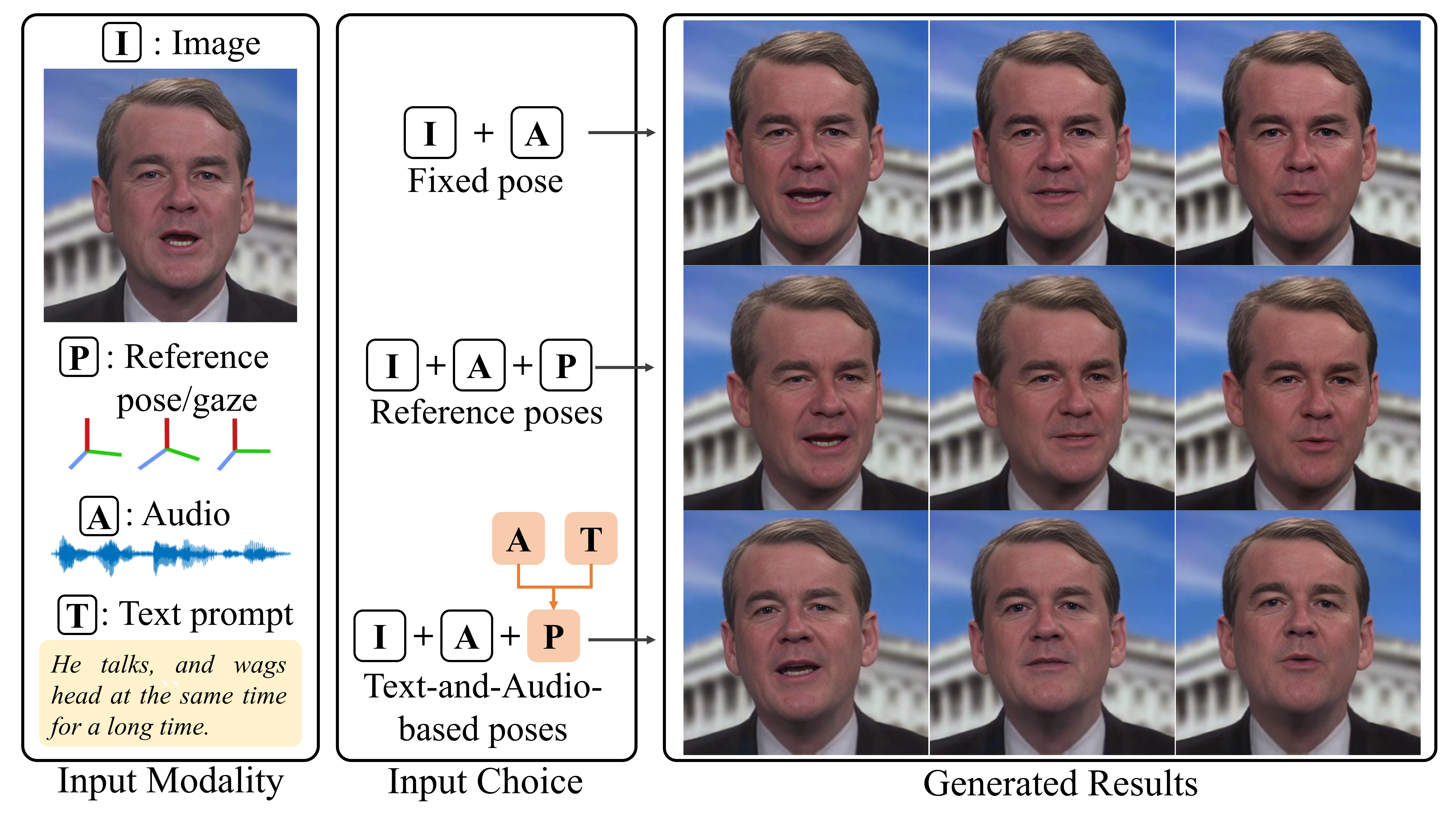
Although audio-driven talking face generation has witnessed significant advances in recent years, two problems remain to be solved. First, the existing models cannot control the long-term head actions as humans expect, because the audio can only provide short-term cues, such as the rhythms and sentiments, for head movements. Second, generating long-term head poses and ensuring accurate lip motions remain challenging due to the difficulty in harnessing the optimization process for large-scale head movements and small-scale mouth motions. In this study, we propose a novel method to address these issues. First, to alleviate the limitations of audio conditions, we propose a Pose Latent Diffusion (PLD) model that generates head motions from two types of input modalities: audio and user-controlled text prompts. The audio provides short-term rhythm correspondence with the head movements, while the text prompts describe the long-term semantics of head motions. Second, we propose a refinement-based learning strategy to synthesize head movements and accurate lip motions using two cascaded networks, namely CoarseNet and RefineNet. The CoarseNet estimates coarse global motions to produce animated images with changed poses, and the RefineNet progressively estimates finer lip motions from low to high resolutions, yielding improved lip-synchronization performance. Experiments demonstrate that our method can achieve better pose diversity and realness compared to audio-based pose generation baselines, and our video generator model outperforms state-of-the-art methods in synthesizing natural head motions.