|
Jun Ling I am currently a Ph.D candidate at MediaLab in Shanghai Jiao Tong University, supervised by Prof. Li Song. My current research focuses on visual content creation, e.g., including talking head synthesis, face animation, articulated human generation. In Mar. 2021, I obtained my MSc degree at Shanghai Jiao Tong University, where I was advised by Prof. Li Song and Xiao Gu. I did my BSc at University of Science and Technology of China. I was fortunate to worked as a research intern at MSRA, and hopefully worked with Xu Tan and Runnan Li in 2021. I'm interested in computer vision and image processing. My previous research is mainly about generating facial videos from multiple driving sources. I am open and happy to share and collaborate with you in related fields. |

|
Selected PublicationsFull paper list can be found on Google Scholar. |
|
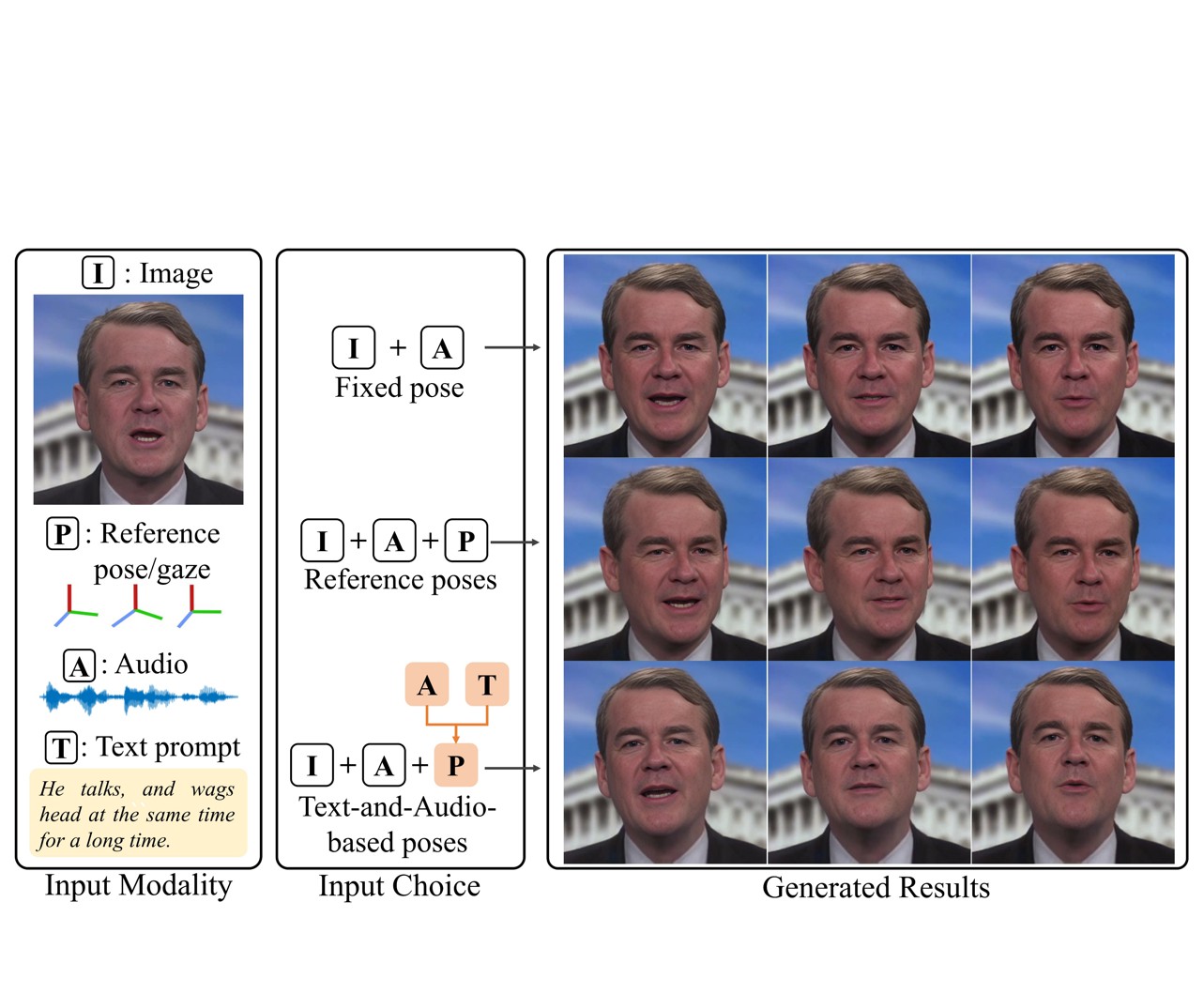
PoseTalk: Text-and-Audio-based Pose Control and Motion Refinement for One-Shot Talking Head Generation
Jun Ling, Yiwen Wang, Han Xue, Rong Xie, Li Song Preprint, 2024 Project page / Code (coming!) / arXiv |
|
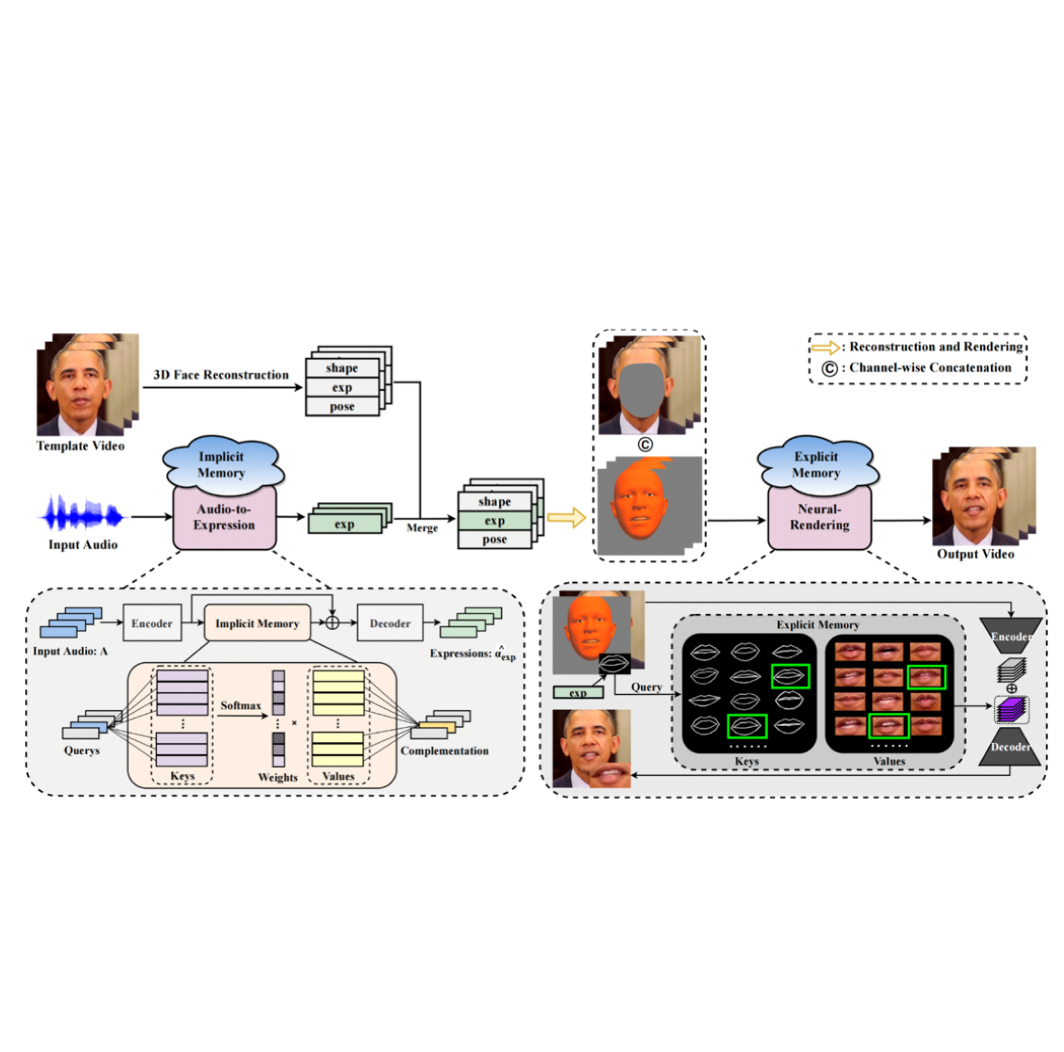
Memories Are One-to-many Mapping Alleviators in Talking Face Generation
Anni Tang, Tianyu He, Xu Tan, Jun Ling, Runnan Li, Sheng Zhao, Li Song, Jiang Bian IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 Demo / paper Introducing explicit memory and implicit memory for high-quality and lip-synchronized talking head generation. |
|
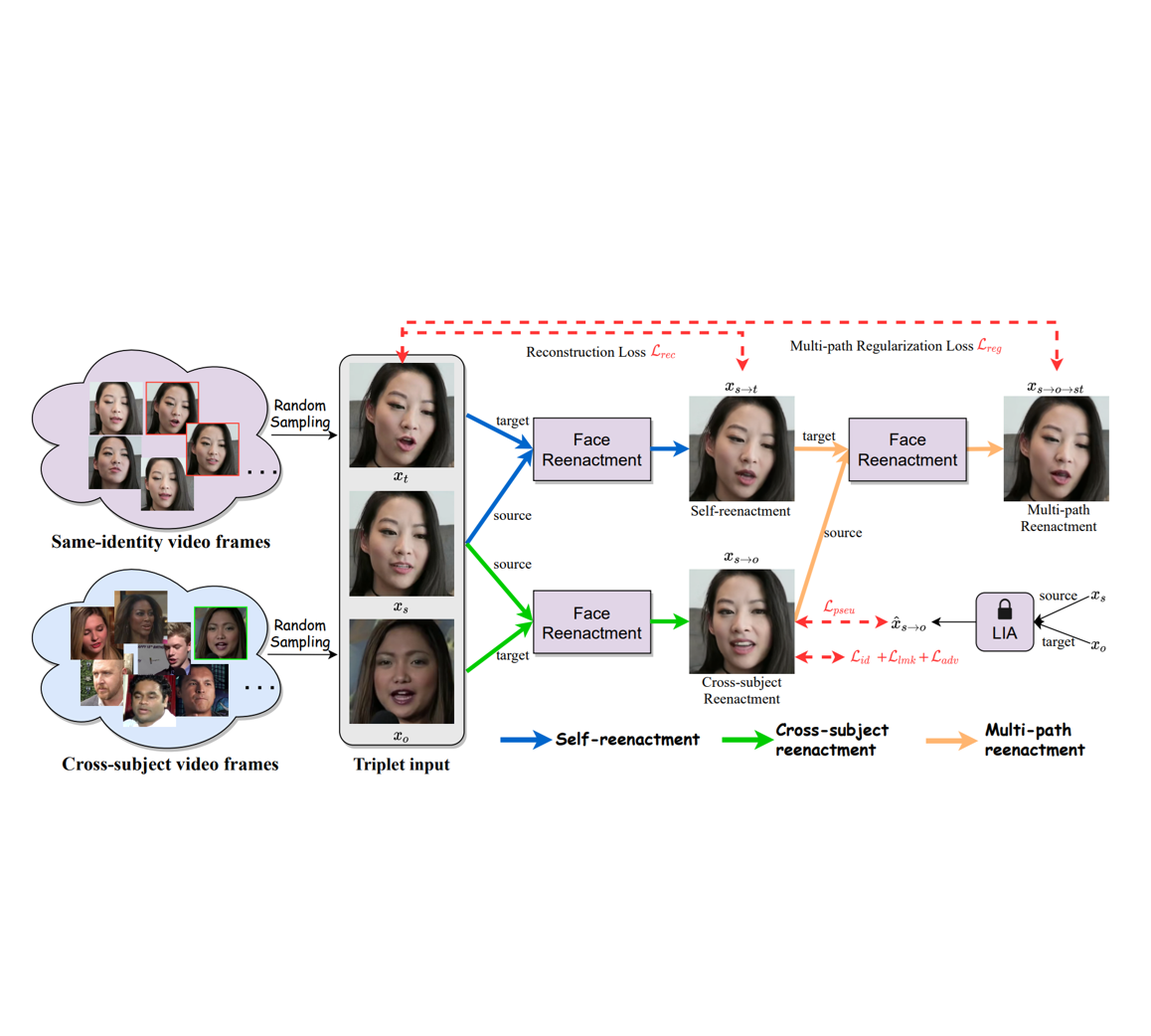
ViCoFace: Learning Disentangled Latent Motion Representations for Visual-Consistent Face Reenactment
Jun Ling, Han Xue, Anni Tang, Rong Xie, Li Song ACM Transactions on Multimedia Computing, Communications and Applications (TOMM), 2024 Project page / Code / paper Proposing motion disentanglement and effective mixed training strategies for appearance-preservable face reenactment |
|
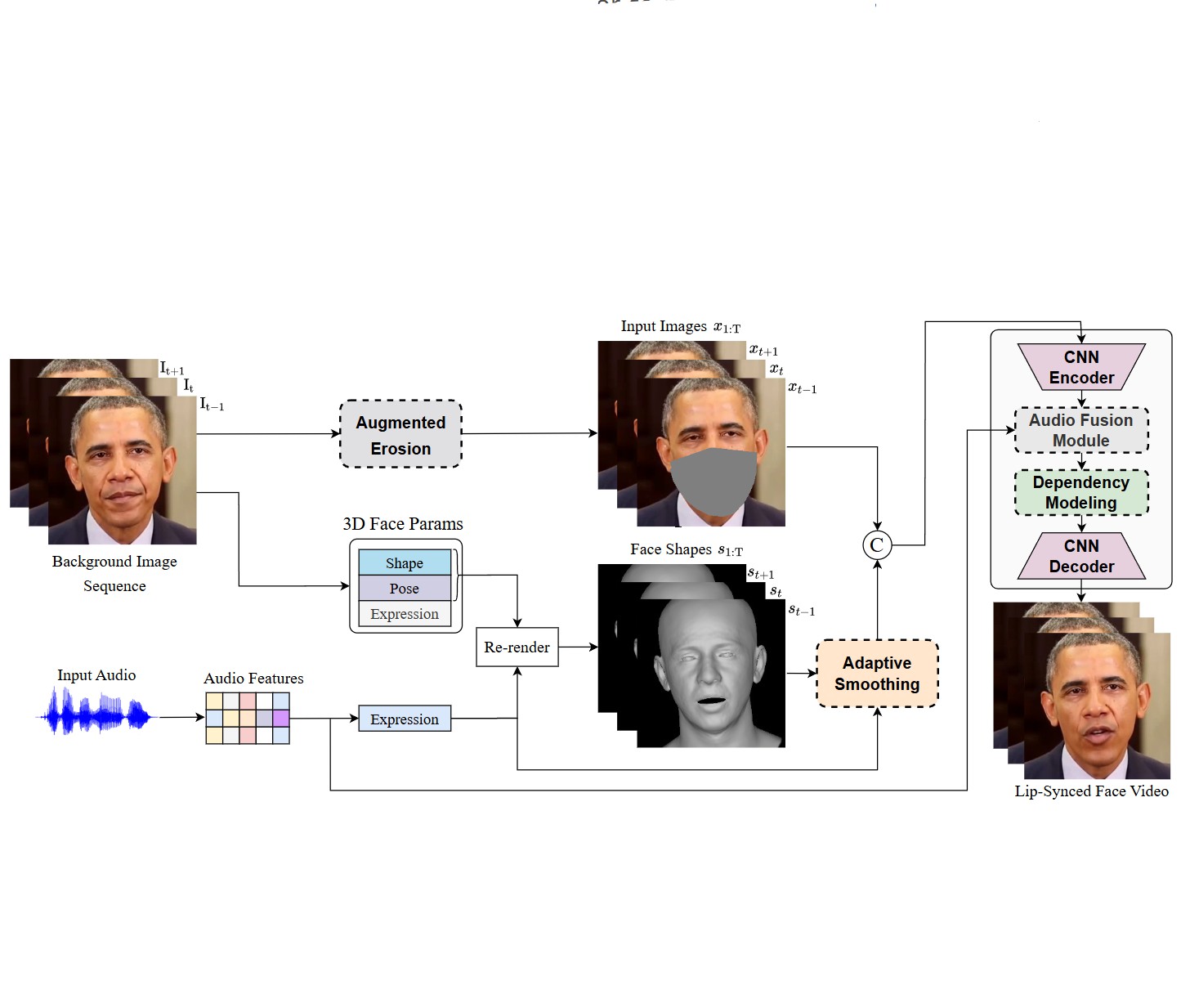
StableFace: Analyzing and Improving Motion Stability for Talking Face Generation
Jun Ling, Xu Tan, Liyang Chen, Runnan Li, Yuchao Zhang, Sheng Zhao, Li Song IEEE Journal of Selected Topics in Signal Processing, 2023 Project page / arXiv Introducing systematical solutions for motion-stable talking face generation. |
|
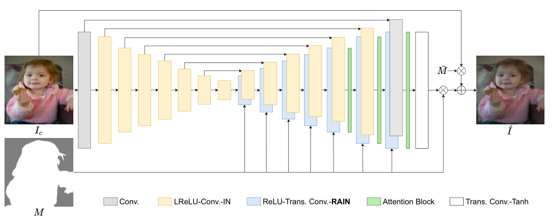
Region-aware Adaptive Instance Normalization for Image Harmonization
Jun Ling, Han Xue, Li Song, Rong Xie, Xiao Gu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021 Code / arXiv Proposing region-wise adaptive instance normalization for image harmonization. |
|
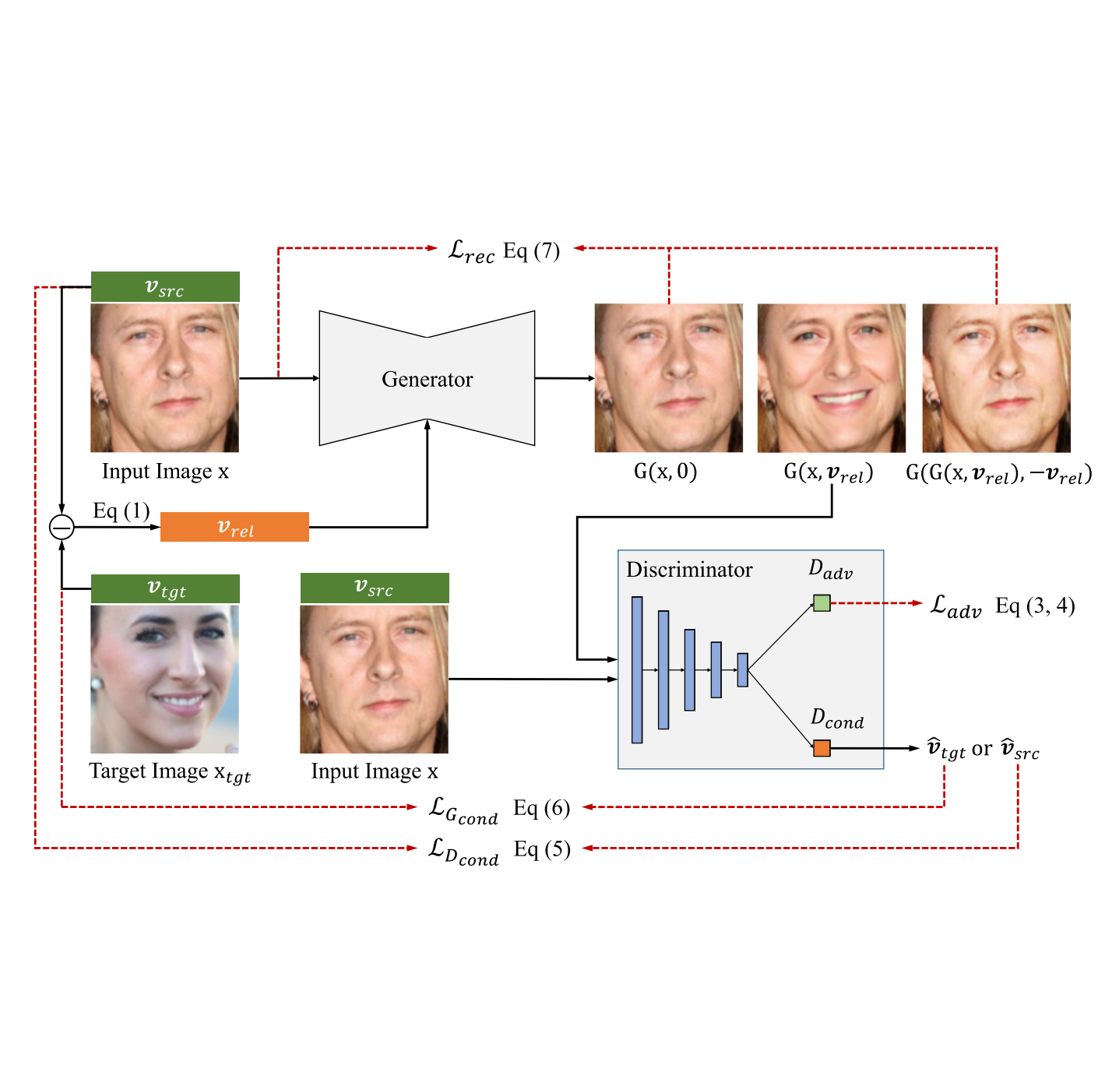
Toward Fine-grained Facial Expression Manipulation
Jun Ling, Han Xue, Li Song, Shuhui Yang, Rong Xie, Xiao Gu European Conference on Computer Vision (ECCV), 2020 Code / arXiv Adopting relative facial action units as expression editing guidance. |
|
This page is borrowd from Jon Barron. |